I am moving my blogg to : besimondata.com and I hope you will follow me there as well.
See you there!
Besim

Data Science blog
fredag 20. januar 2017
onsdag 28. desember 2016
How 10 industries are using big data to win big
Two and a half quintillion bytes or 2,500,000,000,000,000,000 bytes. That’s how much data humanity generates every single day. And the amount is increasing; we’ve created 90% of the world’s data in the last two years alone.
It should come as no surprise, then, that businesses today are drowning in data. That’s because much of that data is unstructured; it takes the form of documents, social media content and other qualitative information that doesn’t reside in conventional databases and is can’t be parsed by traditional algorithms or machine analysis.
But, thanks to new cognitive computing services, that’s changing fast.
New Tools, New Insights
Cognitive services not only cut through the deluge of data, but also bring meaning to it through human-like understanding of natural language queries. They’re helping businesses across a broad range of industries respond to the needs of their customers like never before, driving increased revenue while reducing costs.

The industries boosting bottom lines and setting new standards for customer service include telecommunications, manufacturing, fitness, retail, insurance, banking, finance, government, healthcare and the travel industry.
Here’s an overview of how these industries are making all of their data work for them:
1. Telecommunications
A major telecommunications service provider uses cognitive services to index thousands of documents, images and manuals in mere minutes, in order to help 40,000 call center agents solve customer issues more effectively. The company realizes a savings of $1 for every second shaved off the average handling time per call—or $1 million a year.
2. Manufacturing
A specialty sports manufacturer was challenged to fine-tune production in order to eliminate inventory overruns and create better products while saving money. Now, thanks to newly accessible data, the company produces 900 different kinds of skis to match customer personality, preference, and snow conditions—giving customers exactly what they want and meeting the company’s goals for lower inventory and expenses.
3. Retail
Data-driven, personalized customer experiences enabled by cognitive technology are helping a major clothing retailer not only provide outstanding service, but also drive revenue at more than 225 stores. To design a better in-store experience, the company uses sensor and Wi-Fi data to track who comes in, what aisles they visit and for how long. The company also analyzes social media data from millions of followers to improve marketing and product design.
4. Fitness
Cognitive services aren’t just for customer service agents and manufacturers; they can directly serve customers, too. A sports apparel and connected fitness company uses data to power the world’s first cognitive fitness coaching mobile app. The app collects data on users’ workouts, calories burned and more in order to act as a “virtual coach” to help them meet their health goals.
5. Insurance
An international insurance company uses cognitive services to reduce the time needed to process complex claims from two days to just 10 minutes. The company is also using data to identify and eliminate hundreds of millions of dollars in fraud and leakage. The result: a more customer-centric and profitable company.
6. Banking
A consumer banking chain in New Zealand is using data collected and analyzed by cognitive computing to more than double customer engagement online—from 40% to 92%, with a 30% increase in online banking. With a view into customer sentiment as well as data on revenue generation per product held, agents can provide more personalized customer service. Customers can log on to mobile devices to perform more than 120 functions, including applying for a mortgage. As a result, mobile usage is up 45%.
7. Finance
Cognitive technology is empowering the financing arm of a major auto manufacturer to develop insights about more than four million individual customers in seconds. The system combines unstructured content and conventional data from internal and public sources, then displays all meaningful information based on a the user’s job description. Agents can thus provide customers with more comprehensive information faster, and the company can maintain data security.
<iframe width="560" height="315" src="https://www.youtube.com/embed/cE2El1MOV_w?list=UUJW18YbgMROweH2s8vWkl8g" frameborder="0" allowfullscreen></iframe>
8. Government
A U.S. state government is using data to enhance the services delivered to millions of its citizens. Cognitive services enable citizens to quickly and easily search hundreds of thousands of documents, including important new insurance requirements. This allowed the state to achieve its goal of helping citizen navigate more than 1 million pages, while saving tens of thousands of dollars in upgrade costs.
9. Healthcare
A large healthcare company is using data and cognitive computing to extract key insights from unstructured patient medical history—including physician notes and dictation—covering 1.35 million annual outpatient visits, 68,000 hospital admissions and 265,000 emergency room visits. The trends, patterns and other important information captured from this data help clinicians identify patients at risk for chronic disease, critical to both improving treatment and reducing readmission.
<iframe width="560" height="315" src="https://www.youtube.com/embed/bLe1GBs7S3M" frameborder="0" allowfullscreen></iframe>
10. Travel
An international airline has found a way to use cognitive services to significantly enhance the customer experience. Flight crews now use mobile devices to access customer data, including allergies, food and seat preferences and previous travel history to offer truly personalized service. To show its customers that it values their information, the airline has launched a first-of-its-kind customer insights program that rewards those who share data by offering them airline miles.
A Vital Competitive Advantage
As the data deluge grows day by day, it presents greater opportunities for companies to drive more personalized and customer-centered service while boosting revenue and efficiency. But these actionable insights will only be available to companies that leverage advanced data analytics and cognitive computing to collect and parse unstructured data. Those who fail to take advantage of cognitive services risk getting left behind.
To learn more about trends in data and cognitive computing download IBM’s Evolution of Enterprise Search Webinar series.
mandag 19. desember 2016
Modernizing data description
Illumination
In the recent times, few words (like Robotics, Artificial Intelligence, Analytics, Data Mining, Machine Learning, etc.) are powerful (sometime confusing) in IT industry.
In this competitive world, it is highly important for any software engineer to understand the concepts and usage of the emerging fields. Itz essential to survive in the rapid growth IT industry.
Based on my (l)earning through the premium technology institute and related work experience, I'm writing this article with the strong fundamentals and concepts around it.
Key Areas
In my view, these emerging fields are categorized into 4 key areas. Letz see them in details:
1. Statistics
We all know that Statistics is a study of how to collect, organizes, analyze, and interpret numerical information from data. Statistics can slip into two taxonomy namely:
1. Descriptive Statistics
2. Inferential Statistics
Descriptive statistics involves method of organizing, summering and picturing information from data. Familiar examples are Tables, Graphs, Averages. Descriptive statistics usually involve measures of central tendency (mean, median, mode) and measures of dispersion (variance, standard deviation, etc.)
Inferential statistics invokes method of using information from sample to draw conclusion about the population. Common terminologies are "Margin of error", "Statically Significant".
2. Artificial Intelligence (AI)
AI is a broad term referring to computers and systems that are capable of essentially coming up with solutions to problems on their own. The solutions aren’t hard-coded into the program; instead, the information needed to get to the solution is coded and AI (used often in medical diagnostics) uses the data and calculations to come up with a solution on its own.
 As depicted above, AI is the super set of the listed components and so itz a vast area to explore.
As depicted above, AI is the super set of the listed components and so itz a vast area to explore.3. Machine Learning (ML)
Machine learning is capable of generalizing information from large data sets, and then detects and extrapolates patterns in order to apply that information to new solutions and actions. Obviously, certain parameters must be set up at the beginning of the machine learning process so that the machine is able to find, assess, and act upon new data

4. Data Mining
Data mining is an integral part of coding programs with the information, statistics, and data necessary for AI to create a solution

In the traditional reporting model, the data source is retrospective to look back and examines the exposure of the existing information. Descriptive analytics are useful because they allow us to learn from past behaviors, and understand how they might influence future outcomes.
Inter Connectivity
On connecting the dots of the above said 4 platforms, Artificial Intelligence is the foundation which is followed by Machine Learning, Statistics and Data Mining, chronologically. In simple term, AI (Artificial Intelligence) is the super set of all paradigm.

Artificial Intelligence is a science to develop a system or software to mimic human to respond and behave in a circumference.
Evolution of Statistics, AI, ML and Data Mining is depicted in the below chart.

Need of Chat Bot
On analyzing where people really spend time, you’ll probably get the details where the users are. Chat Bot is the low hanging fruit in terms of business & technical opportunity.
A Chat Bot can be easily built into any major commonly used chat product like Facebook Messenger or Slack. Latest industry data indicates that the end users reached more usage band of messenger apps than social networks, as depicted below:

We've another dimension of Messenger App usage. According to Statista, most popular global mobile messenger apps usage is pointed below, as of April 2016. Itz based on number of monthly active users (in millions).

Next Gen - Messaging
If you think about your daily interactions online, it won’t be that surprising – you use Slack or Skype to communicate with your colleagues at work, you talk to your closest friends on Facebook in Messenger, you probably have several chats with different groups of your friends depending on interests etc.

Chat Bots shift the shopping experience from browsing (web/retail stores) to recommendation. Bots learn about you, much like a trusted friend or personal shopper.
Chat Bot in Business
In Artificial Intelligence, Chat Bot plays a key tool by providing feedback to users on purchases with customer service agents on hand to provide further assistance.
In China, not only is WeChat used by close to two thirds of 16-24 year-old online consumers, but the service has capitalized on its massive market share by offering functionality well beyond simple messaging by attempting to insert itself into as many stations along the purchase journey as possible.
As the major part of digital consumers’ purchase journeys and online lives, Chat Bot will need to be non-intrusive, obviously beneficial to the user and, perhaps most importantly, present themselves as an honest assistant, not an advertisement in disguise.
As the summation of my analysis, 2 key business benefits of Chat Bot usage:
1. High automation in manual contact center business; leads to drastic cost reduction
2. Continuous improvement (on usage) is possible with the usage of Machine Learning in AI intelligent Chat Bot
Conclusion
What you research today may eventually underpin how you deploy a successful Chat Bot application for your business sooner rather than later once all the kinks get worked out. Get ready, folks !!
søndag 11. desember 2016
Personal Finance Application
Make Personal Finance fun again by automated segmentations, benchmarking gamification and automated machine learning budgeting tool.
ELA AS is newly founded startup with a clear mission to make use of data to benefit humanity. #DataForGood is our core value and a hashtag of our activities in social media. We have started with four projects, but we hope to continue with some more:
1. Personal Finance Digital Assistant which is an add-on solution to your digital bank account that gives you better picture of personal finances based on bench-marking against predefined data set of your segmentation (ex: income range, family members, region you live etc.) and fully automatized data input for all segments: cost, income and balance. This will include a machine learning (ML) algorithm that will suggest you the best way to save and invest money, how to overcome a financial difficulty and how to perform in budgeting your economy the best way.
We will soon be in Kickstarter and I hope that you will support our project!
The Deception of Supervised Learning
Do models or offline datasets ever really tell us what to do? Most application of supervised learning is predicated on this deception.
Imagine you're a doctor tasked with choosing a cancer therapy. Or a Netflix exec tasked with recommending movies. You have a choice. You could think hard about the problem and come up with some rules. But these rules would be overly simplistic, not personalized to the patient or customer. Alternatively, you could let the data decide what to do!
The ability to programmatically make intelligent decisions by learning complex decision rules from big data is a primary selling point of machine learning. Leaps forward in the predictive accuracy of supervised learning techniques, especially deep learning, now yield classifiers that outperform human predictive accuracy on many tasks. We can guess how an individual will rate a movie, classify images, or recognize speech with jaw-dropping accuracy. So why not make our services smart by letting the data tell us what to do?
Here's the rub.
While the supervised paradigm is but one of several in the machine learning canon, nearly all machine learning deployed in the real world amounts to supervised learning. And supervised learning methods doesn't tell us to doanything. That is, the theory and conception of supervised learning addresses pattern recognition but disregards the notion of interaction with an environment altogether.
[Quick crash course: in supervised learning, we collect a dataset of input-output (X,Y) pairs. The learning algorithm then uses this data to train a model. This model is simply a mapping from inputs to outputs. Now given a new input (such as a [drug,patient] pair), we can predict a likely output (say, 5-year survival). We determine the quality of the model by assessing its performance (say error rate or mean squared error) on hold-out data.]

Now suppose we train a model to predict 5-year survival given some features of the patient and the assigned treatment protocol. The survival model that we train doesn't know why drug A was prescribed to some patients and not others. And it has no way of knowing what will happen when you apply drug A to patients who previously wouldn't have received it. That's because supervised learning relies on the i.i.d. assumption. In short, this means that we expect the future data to be distributed identically like the past. With respect to temporal effects, we assume is that the distribution of data is stationary. But when we introduce a decision protocol based on a machine learning model to the world, we change the world, violating our assumptions. We alter the distribution of future data and thus should expect to invalidate our entire model.
For some tasks, like speech recognition, these concerns seem remote. Use of a voice transcription tool might not, in the short run, change how we speak. But in more dynamic decision-making contexts, the concerns should be paramount. For example, Rich Caruana of Microsoft Research showed a real-life model trained to predict risk of death for pneumonia patients. Presumably this information could be used to aid in triage. The model however, showed that asthma was predictive of lower risk. This was a true correlation in the data, but it owed to the more aggressive treatment such co-morbid patients received. Put simply, a researcher taking actions based on this information would be mistaking correlation for causation. And if a hospital used the risk score for triage, they would actually recklessly put the asthma patients at risk, thus invalidating the learned model model.
Supervised models can't tell us what to do because they fundamentally ignore the entire idea of an action. So what do people mean when they say that they act based on a model? Or when they say that the model (or the data) tells them what to do? How is Facebook's newsfeed algorithm curating stories? How is Netflix's recommender system curating movies?
Usually this means that we strap on some ad-hoc decision protocol to a predictive model. Say we have a model that takes a patient and a drug and predicts the probability of survival. A typical ad hoc rule might say that we should give the drug that maximizes the predicted probability of survival.

But this classifier is contingent on the historical standard of care. For one drug, a model might predict better outcomes because the drug truly causes better outcomes. But for others causality might be reversed, or the association might owe to unobserved factors. These kinds of actions encode ungrounded assumptions mistaking correlative association for causal relationships. While oncologists are not so reckless as to employ this reasoning willy-nilly, it's precisely the logic that underlies less consequential recommender systems all over the internet. Netflix doesn't account for how its recommendations influence your viewing habits, and Facebook's algorithms likely don't account for the effects of curation on reader behavior.
The failure to account for causality or interaction with the environment are but two among many deceptions underlying the modern use of supervised learning. Other, less fundamental, issues abound. For example, we often optimize surrogate objectives that only faintly resemble our true objectives. Search engines assume that mouse clicks indicate accurately answered queries. This means that when, in a momentary lapse of spine, you click on a celebrity break-up story after searching for an egg-salad recipe, the model registers a job a well done.
Some other issues to heap on the laundry list of common deceptions:
- Disregarding real-life cost-sensitivity
- Erroneous interpretation of predicted probabilities as quantifications of uncertainty
- Ignoring differences between constructed training sets and real world data
The overarching point here is that problem formulation for most machine learning systems can be badly mismatched against the real-world problems we're trying to solve. As detailed in my recent paper, The Mythos of Model Interpretability, it's this mismatch that leads people to wonder whether they can "trust" machine learning models.
Some machine learners suggest that the desire for an interpretation will pass - that it reflects an unease which will abate if the models are "good enough". But good enough at what? Minimizing cross-entropy loss on a surrogate task on a toy-dataset in a model that fundamentally ignores the decision-making process for which a model will be deployed? The suggestion is naive, but understandable. It reflects the years that many machine learners have spent single-mindedly focused on isolated tasks like image recognition. This focus was reasonable because these offline tasks were fundamental obstacles themselves, even absent the complication of reality. But as a result, reality is a relatively new concept to a machine learning community that increasingly rubs up against it.
So where do we go from here?
Model Interpretability
One solution is to go ahead and throw caution to the wind but then to interrogate the models to see if they're behaving acceptably. These efforts seek to interpret models to mitigate the mismatch between real and optimized objectives. The idea behind most work in interpretability is that in addition to the predictions required by our evaluation metrics, models should yield some additional information, which we term an interpretation. Interpretations can come in many varieties, notably transparency and post-hoc interpretability. The idea behind transparency is that we can introspect the model and determine precisely what it's doing. Unfortunately, the most useful models aren't especially transparent. Post-hoc interpretations, on the other hand, address techniques to extract explanations, even those from models we can't quite introspect. In the Mythos paper (https://arxiv.org/abs/1606.03490), I offer a broad taxonomy of both the objectives and techniques for interpreting supervised models.
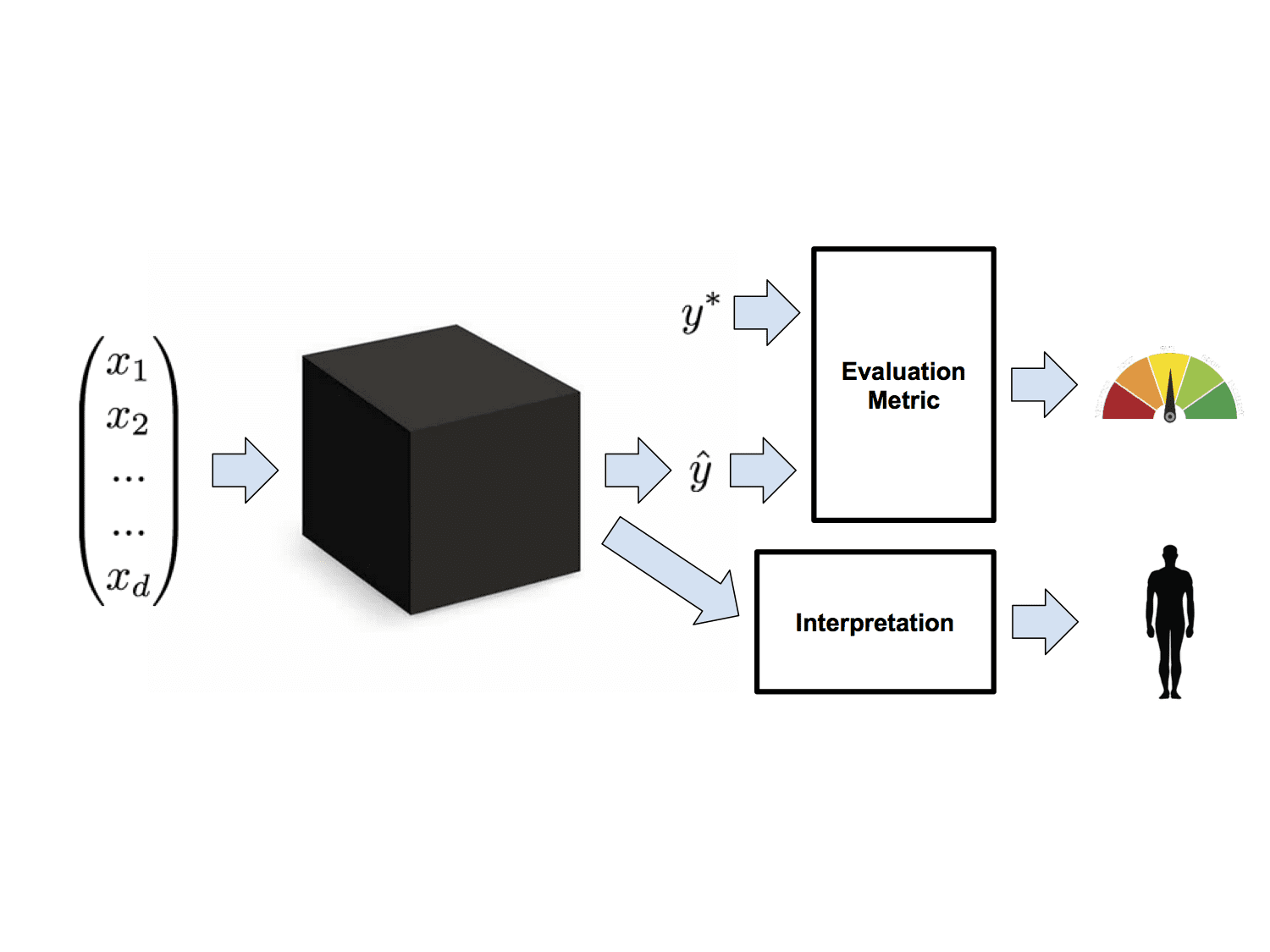
Upgrade to More Sophisticated Paradigms of Learning
Another solution might be to close the gap between the real and modeled objectives. Some problems, like cost sensitivity, can be addressed within the supervised learning paradigm. Others, like causality, might require us to pursue fundamentally more powerful models of learning. Reinforcement learning (RL), for example, directly models an agent acting within a sequential decision making process. The framework captures the causal effects of taking actions and accounts for a distribution of data that changes per modifications to the policy. Unfortunately, practical RL techniques for sequential decision-making have only been reduced to practice on toy problems with relatively small action-spaces. Notable advances include Google Deepmind's Atari and Go-playing agents.
Several papers by groups including Steve Young's lab at Cambridge (paper), the research team at Montreal startup Maluuba (arxiv.org/abs/1606.03152), and my own work with Microsoft Research's Deep Learning team (arxiv.org/abs/1608.05081), seek to extend this progress into the more practically useful realm of dialogue systems.
Using RL in critical settings like medical care poses its own thorny set of problems. For example, RL agents typically learn by exploration. You could think of exploration as running an experiment. Just like a doctor might run a randomized trial, the RL agent periodically takes randomized actions, using the information gained to guide continued improvement of its policy. But when is it OK to run experiments with human subjects? To do any research on human subjects, even the most respected researchers are required to submit to an ethics board. Can we then turn relatively imbecilic agents loose to experiment on human subjects absent oversight?
Conclusions
Supervised learning is simultaneously unacceptable, inadequate, and yet, at present, the most powerful tool at our disposal. While it's only reasonable to pillory the paradigm with criticism, it remains nonetheless the most practically useful tool around. Nonetheless I'd propose the following takeaways:- We should aspire to unseat the primacy of strictly supervised solutions. Improvements in reinforcement learning offer a promising alternative.
- Even within the supervised learning paradigm, we should work harder to eliminate those flaws of problem formulation that are avoidable.
- We should remain suspicious of the behavior of live systems, and devise mechanisms to both understand them and provide guard-rails to protect against unacceptable outcomes.
 Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. He is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, and is a Contributing Editor at KDnuggets.
Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. He is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, and is a Contributing Editor at KDnuggets.
Related:
- The Hard Problems AI Can’t (Yet) Touch
- Does Deep Learning Come from the Devil?
- MetaMind Competes with IBM Watson Analytics and Microsoft Azure Machine Learning
- Deep Learning and the Triumph of Empiricism
- The Myth of Model Interpretability
- (Deep Learning’s Deep Flaws)’s Deep Flaws
- Data Science’s Most Used, Confused, and Abused Jargon
mandag 28. november 2016
Start-up of the week: Instalocate- A chatbot that claims to make your travel more comfortable!

Img Source: Instalocate | www.instalocate.com
Did you know that every time your flight gets delayed your airlines owes you a compensation? Have you ever been denied boarding because the flight was overbooked? Are you aware of your rights as a flyer? Many a times we overlook on these issues and incur heavy losses, but not anymore. The one company founded by Stanford University and Indian Institute of Management (IIM) alumni in June 2016, is building an AI powered travel assistant just for you!
Instalocate– the name as it goes by – promises to watch all that for you by building a cutting-edge technology that can solve all your travel problems and make your journey comfortable. No more panicking and rushing to the airline counters, standing in long queues or calling the customer care if your flight gets delayed or baggages do not come on time! Instalocate promises to constantly monitor your travel and predict and solve the travel problems.
Not just that, it would also protect your rights as a customer and go after airlines to get your due compensation in case of any mishap.
How wonderful is that? Having a digital personal assistant that can make your journey comfortable and be always there to answer all your questions in an instant!
Talking to AIM, one of its founders Pallavi Singh revealed that the idea of Instalocate was conceived out of all the unfortunate incidences that she and her husband had personally faced.
“Anything that can go wrong has gone wrong with us. Flights have gotten delayed, we have missed connections, baggage was lost. And that’s when we realised that, most of the travel apps are working in pre-booking and there is no one to help you when things like this go wrong. Dealing with the airlines was the biggest nightmare amidst this”, she said.
And that’s how the journey to Instalocate took off with an idea of building an assistant which could help during the travel woes and deals with the airline on your behalf. Pallavi confesses “At so many times, we felt so frustrated with the airlines that we wanted to sue them for compensation, for all the trouble we went through. But we never did- mainly because we never had the time to deal with the airlines.”
With Instalocate, all you have to do is share your flight details and it will predict when you might need something and would send the contextual information automatically. Just ask your assistant anything from your flight status to the free Wi-Fi availability in the airport! That’s not all, if your family is worried about you, the assistant can pinpoint your exact location in the air. They don’t have to anxiously wait outside the airport checking their phones again and again! After reaching your destination, your cab will be waiting for you.
How is all of it achieved? Talking about the integration of artificial intelligence to Instalocate, Pallavi said “It is a predictive engine which will predict when the airlines owe you compensation. Unlike others we don’t wait for you to search for that information rather we will bring it to you. We are also building in-house NLP which makes it easier for an end user to talk to us, just as they would talk to a friend.”
There is no doubt that the bot has been received well by its users. “We have only launched our first product and the people are loving it”, marked Pallavi. Citing a use case, she said “One of our power users recently got 800 dollars from British Airways for flight delay with the help of Instalocate.”
However, the journey to its popularity was not easy. Pallavi notes that making was not as challenging as marketing. “Bots is still a new concept for people and popularizing it is a big problem”, she added.
Well, despite the challenges, Instalocate has done quite well for itself and is growing at a rate of 60 month over month with a pretty high retention rate.
This digital personal assistant is available to make your journey comfortable and answer your questions in an instant. Talk to Instalocate within facebook at m.me/instalocate for a hassle-free travel now. There is no need to install the app separately, which adds to the many perks this travel bot has!
søndag 27. november 2016
The company that perfects Data Visualization in Virtual Reality will be the next Unicorn
Fortune 500 companies are investing staggering amounts into data visualization. Many have opted for Tableau, Qlik, MicroStrategy, etc. but some have created their own in HTML5, full stack JavaScript, Python, and R. Leading CIOs and CTOs are obsessed with being the first adopters in whatever is next in data visualization.
The next frontier in data visualization is clearly immersive experiences. The 2014 paper "Immersive and Collaborative Data Visualization Using Virtual Reality Platforms" written by CalTech astronomers is a staggeringly large step in the right direction. In fact, I am shocked that 1 year later I have not seen a commercial application of this technology. You can read it here: http://arxiv.org/ftp/arxiv/papers/1410/1410.7670.pdf
The key theme that I hear at technology conferences lately is the need to focus on analytics, visualization and data exploration. The advent of big data systems such as Hadoop and Spark has made it.

Picture Source: VR 2015 IEEE Virtual Reality International Conference
possible - for the first time ever - to store Petabytes of data on commodity hardware and process this data, as needed, in a fault tolerant and incredibly quick fashion. Many of us fail to understand the full implications of this inflection point in the history of computing.
Storage is decreasing in cost every year, to the point where you can now have multiple GB on a USB drive that 10 years ago you could only store a few MBs. Gigabit internet is being installed in cities all over the world. Spark uses the concept of in memory distributed computation to perform at 10X map reduce for gigantic datasets and is already being used in production by Fortune 50 companies. Tableau, Qlik, MicroStrategy, Domo, etc. have gained tremendous market share as companies that have implemented Hadoop components such as HDFS, Hbase, Hive, Pig, and Map Reduce are starting to wonder "How I can I visualize that data?"
Now think about VR - probably the hottest field in technology at this moment. It has been more than a year since Facebook bought Oculus for 2Billion and we have seen Google Cardboard burst onto the scene. Applications from media companies like the NY Times are already becoming part of our every day lives. This month at the CES show in Las Vegas, dozens of companies were showcasing virtual reality platforms that improve on the state of the art and allow for a motion-sickness free immersive experience.
All of this combines into my primary hypothesis - this is a great time to start a company that would provide the capability for immersive data visualization environments to businesses and consumers. I personally believe that businesses and government agencies would be the first to fully engage in this space on the data side, but there is clearly an opportunity in gaming on the consumer side.
Personally, I have been so taken by the potential of this idea that I wrote a post in this blog about the “feeling” of being in one of these immersive VR worlds.
http://sarcastech.tumblr.com/post/136459105843/data-art-an-immersive-virtual-reality-journey
The post describes what it would be like to experience data with not only vision, but touch and sound and even smell.
Just think about the possibilities of examining streaming data sets, that currently are being analyzed with tools such as Storm, Kafka, Flink, and Spark Streaming as a river flowing under you!
The strength of the water can describe the speed of the data intake, or any other variable that is represented by a flow - stock market prices come to mind.
The possibilities for immersive data experiences are absolutely astonishing. The CalTech astronomers have already taken the first step in that direction, and perhaps there is a company out there that is already taking the next step. That being said, if this sounds like an exciting venture to you, DM me on twitter @beskotw and we can talk.
The next frontier in data visualization is clearly immersive experiences. The 2014 paper "Immersive and Collaborative Data Visualization Using Virtual Reality Platforms" written by CalTech astronomers is a staggeringly large step in the right direction. In fact, I am shocked that 1 year later I have not seen a commercial application of this technology. You can read it here: http://arxiv.org/ftp/arxiv/papers/1410/1410.7670.pdf
The key theme that I hear at technology conferences lately is the need to focus on analytics, visualization and data exploration. The advent of big data systems such as Hadoop and Spark has made it.

Picture Source: VR 2015 IEEE Virtual Reality International Conference
possible - for the first time ever - to store Petabytes of data on commodity hardware and process this data, as needed, in a fault tolerant and incredibly quick fashion. Many of us fail to understand the full implications of this inflection point in the history of computing.
Storage is decreasing in cost every year, to the point where you can now have multiple GB on a USB drive that 10 years ago you could only store a few MBs. Gigabit internet is being installed in cities all over the world. Spark uses the concept of in memory distributed computation to perform at 10X map reduce for gigantic datasets and is already being used in production by Fortune 50 companies. Tableau, Qlik, MicroStrategy, Domo, etc. have gained tremendous market share as companies that have implemented Hadoop components such as HDFS, Hbase, Hive, Pig, and Map Reduce are starting to wonder "How I can I visualize that data?"
Now think about VR - probably the hottest field in technology at this moment. It has been more than a year since Facebook bought Oculus for 2Billion and we have seen Google Cardboard burst onto the scene. Applications from media companies like the NY Times are already becoming part of our every day lives. This month at the CES show in Las Vegas, dozens of companies were showcasing virtual reality platforms that improve on the state of the art and allow for a motion-sickness free immersive experience.
All of this combines into my primary hypothesis - this is a great time to start a company that would provide the capability for immersive data visualization environments to businesses and consumers. I personally believe that businesses and government agencies would be the first to fully engage in this space on the data side, but there is clearly an opportunity in gaming on the consumer side.
Personally, I have been so taken by the potential of this idea that I wrote a post in this blog about the “feeling” of being in one of these immersive VR worlds.
http://sarcastech.tumblr.com/post/136459105843/data-art-an-immersive-virtual-reality-journey
The post describes what it would be like to experience data with not only vision, but touch and sound and even smell.
Just think about the possibilities of examining streaming data sets, that currently are being analyzed with tools such as Storm, Kafka, Flink, and Spark Streaming as a river flowing under you!
The strength of the water can describe the speed of the data intake, or any other variable that is represented by a flow - stock market prices come to mind.
The possibilities for immersive data experiences are absolutely astonishing. The CalTech astronomers have already taken the first step in that direction, and perhaps there is a company out there that is already taking the next step. That being said, if this sounds like an exciting venture to you, DM me on twitter @beskotw and we can talk.
Abonner på:
Innlegg (Atom)