
Do models or offline datasets ever really tell us what to do? Most application of supervised learning is predicated on this deception.
Imagine you're a doctor tasked with choosing a cancer therapy. Or a Netflix exec tasked with recommending movies. You have a choice. You could think hard about the problem and come up with some rules. But these rules would be overly simplistic, not personalized to the patient or customer. Alternatively, you could let the data decide what to do!
The ability to programmatically make intelligent decisions by learning complex decision rules from big data is a primary selling point of machine learning. Leaps forward in the predictive accuracy of supervised learning techniques, especially deep learning, now yield classifiers that outperform human predictive accuracy on many tasks. We can guess how an individual will rate a movie, classify images, or recognize speech with jaw-dropping accuracy. So why not make our services smart by letting the data tell us what to do?
Here's the rub.
While the supervised paradigm is but one of several in the machine learning canon, nearly all machine learning deployed in the real world amounts to supervised learning. And supervised learning methods doesn't tell us to doanything. That is, the theory and conception of supervised learning addresses pattern recognition but disregards the notion of interaction with an environment altogether.
[Quick crash course: in supervised learning, we collect a dataset of input-output (X,Y) pairs. The learning algorithm then uses this data to train a model. This model is simply a mapping from inputs to outputs. Now given a new input (such as a [drug,patient] pair), we can predict a likely output (say, 5-year survival). We determine the quality of the model by assessing its performance (say error rate or mean squared error) on hold-out data.]

Now suppose we train a model to predict 5-year survival given some features of the patient and the assigned treatment protocol. The survival model that we train doesn't know why drug A was prescribed to some patients and not others. And it has no way of knowing what will happen when you apply drug A to patients who previously wouldn't have received it. That's because supervised learning relies on the i.i.d. assumption. In short, this means that we expect the future data to be distributed identically like the past. With respect to temporal effects, we assume is that the distribution of data is stationary. But when we introduce a decision protocol based on a machine learning model to the world, we change the world, violating our assumptions. We alter the distribution of future data and thus should expect to invalidate our entire model.
For some tasks, like speech recognition, these concerns seem remote. Use of a voice transcription tool might not, in the short run, change how we speak. But in more dynamic decision-making contexts, the concerns should be paramount. For example, Rich Caruana of Microsoft Research showed a real-life model trained to predict risk of death for pneumonia patients. Presumably this information could be used to aid in triage. The model however, showed that asthma was predictive of lower risk. This was a true correlation in the data, but it owed to the more aggressive treatment such co-morbid patients received. Put simply, a researcher taking actions based on this information would be mistaking correlation for causation. And if a hospital used the risk score for triage, they would actually recklessly put the asthma patients at risk, thus invalidating the learned model model.
Supervised models can't tell us what to do because they fundamentally ignore the entire idea of an action. So what do people mean when they say that they act based on a model? Or when they say that the model (or the data) tells them what to do? How is Facebook's newsfeed algorithm curating stories? How is Netflix's recommender system curating movies?
Usually this means that we strap on some ad-hoc decision protocol to a predictive model. Say we have a model that takes a patient and a drug and predicts the probability of survival. A typical ad hoc rule might say that we should give the drug that maximizes the predicted probability of survival.

But this classifier is contingent on the historical standard of care. For one drug, a model might predict better outcomes because the drug truly causes better outcomes. But for others causality might be reversed, or the association might owe to unobserved factors. These kinds of actions encode ungrounded assumptions mistaking correlative association for causal relationships. While oncologists are not so reckless as to employ this reasoning willy-nilly, it's precisely the logic that underlies less consequential recommender systems all over the internet. Netflix doesn't account for how its recommendations influence your viewing habits, and Facebook's algorithms likely don't account for the effects of curation on reader behavior.
The failure to account for causality or interaction with the environment are but two among many deceptions underlying the modern use of supervised learning. Other, less fundamental, issues abound. For example, we often optimize surrogate objectives that only faintly resemble our true objectives. Search engines assume that mouse clicks indicate accurately answered queries. This means that when, in a momentary lapse of spine, you click on a celebrity break-up story after searching for an egg-salad recipe, the model registers a job a well done.
Some other issues to heap on the laundry list of common deceptions:
- Disregarding real-life cost-sensitivity
- Erroneous interpretation of predicted probabilities as quantifications of uncertainty
- Ignoring differences between constructed training sets and real world data
The overarching point here is that problem formulation for most machine learning systems can be badly mismatched against the real-world problems we're trying to solve. As detailed in my recent paper, The Mythos of Model Interpretability, it's this mismatch that leads people to wonder whether they can "trust" machine learning models.
Some machine learners suggest that the desire for an interpretation will pass - that it reflects an unease which will abate if the models are "good enough". But good enough at what? Minimizing cross-entropy loss on a surrogate task on a toy-dataset in a model that fundamentally ignores the decision-making process for which a model will be deployed? The suggestion is naive, but understandable. It reflects the years that many machine learners have spent single-mindedly focused on isolated tasks like image recognition. This focus was reasonable because these offline tasks were fundamental obstacles themselves, even absent the complication of reality. But as a result, reality is a relatively new concept to a machine learning community that increasingly rubs up against it.
So where do we go from here?
Model Interpretability
One solution is to go ahead and throw caution to the wind but then to interrogate the models to see if they're behaving acceptably. These efforts seek to interpret models to mitigate the mismatch between real and optimized objectives. The idea behind most work in interpretability is that in addition to the predictions required by our evaluation metrics, models should yield some additional information, which we term an interpretation. Interpretations can come in many varieties, notably transparency and post-hoc interpretability. The idea behind transparency is that we can introspect the model and determine precisely what it's doing. Unfortunately, the most useful models aren't especially transparent. Post-hoc interpretations, on the other hand, address techniques to extract explanations, even those from models we can't quite introspect. In the Mythos paper (https://arxiv.org/abs/1606.03490), I offer a broad taxonomy of both the objectives and techniques for interpreting supervised models.
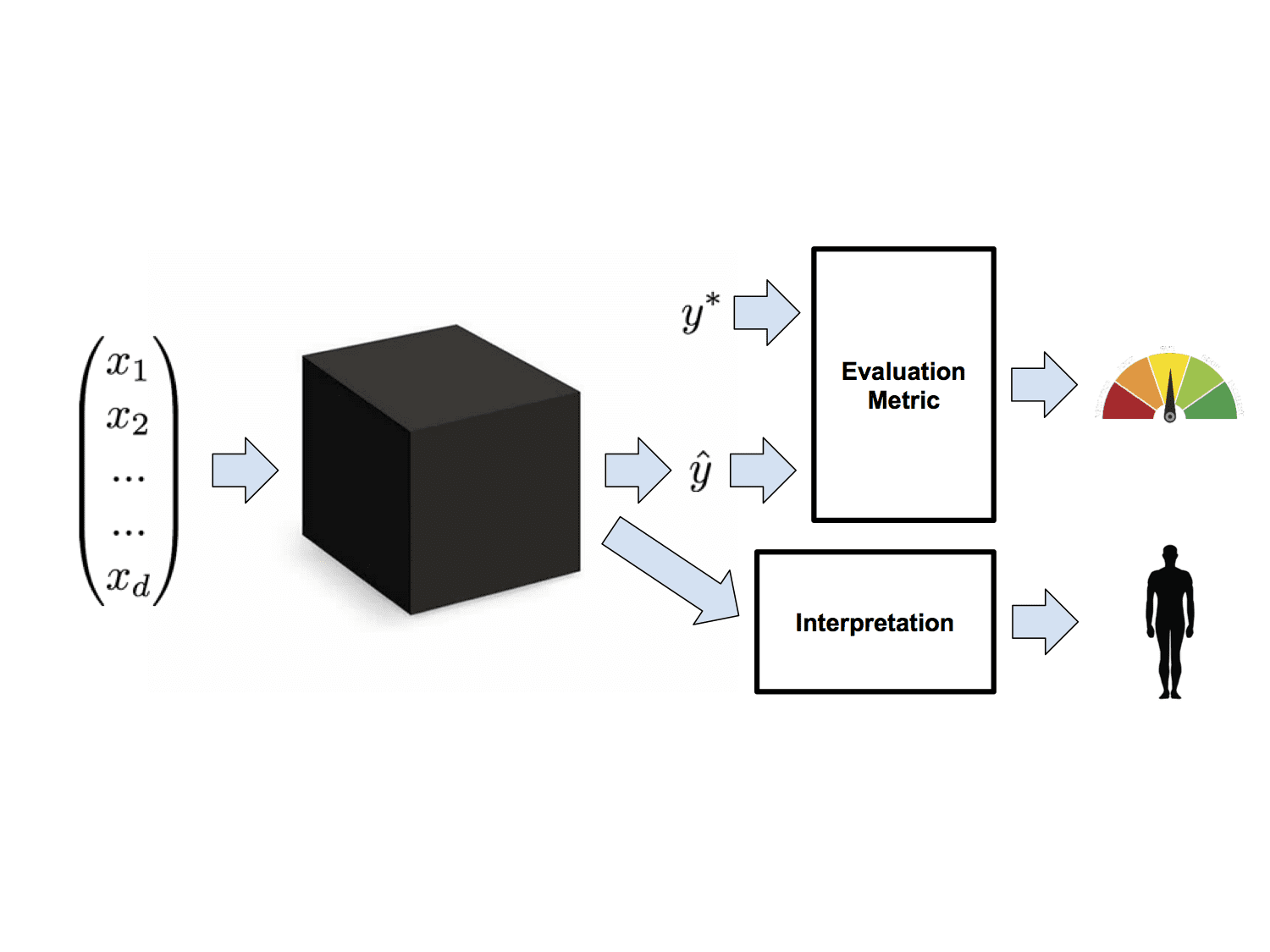
Upgrade to More Sophisticated Paradigms of Learning
Another solution might be to close the gap between the real and modeled objectives. Some problems, like cost sensitivity, can be addressed within the supervised learning paradigm. Others, like causality, might require us to pursue fundamentally more powerful models of learning. Reinforcement learning (RL), for example, directly models an agent acting within a sequential decision making process. The framework captures the causal effects of taking actions and accounts for a distribution of data that changes per modifications to the policy. Unfortunately, practical RL techniques for sequential decision-making have only been reduced to practice on toy problems with relatively small action-spaces. Notable advances include Google Deepmind's Atari and Go-playing agents.
Several papers by groups including Steve Young's lab at Cambridge (paper), the research team at Montreal startup Maluuba (arxiv.org/abs/1606.03152), and my own work with Microsoft Research's Deep Learning team (arxiv.org/abs/1608.05081), seek to extend this progress into the more practically useful realm of dialogue systems.
Using RL in critical settings like medical care poses its own thorny set of problems. For example, RL agents typically learn by exploration. You could think of exploration as running an experiment. Just like a doctor might run a randomized trial, the RL agent periodically takes randomized actions, using the information gained to guide continued improvement of its policy. But when is it OK to run experiments with human subjects? To do any research on human subjects, even the most respected researchers are required to submit to an ethics board. Can we then turn relatively imbecilic agents loose to experiment on human subjects absent oversight?
Conclusions
Supervised learning is simultaneously unacceptable, inadequate, and yet, at present, the most powerful tool at our disposal. While it's only reasonable to pillory the paradigm with criticism, it remains nonetheless the most practically useful tool around. Nonetheless I'd propose the following takeaways:- We should aspire to unseat the primacy of strictly supervised solutions. Improvements in reinforcement learning offer a promising alternative.
- Even within the supervised learning paradigm, we should work harder to eliminate those flaws of problem formulation that are avoidable.
- We should remain suspicious of the behavior of live systems, and devise mechanisms to both understand them and provide guard-rails to protect against unacceptable outcomes.
 Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. He is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, and is a Contributing Editor at KDnuggets.
Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. He is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, and is a Contributing Editor at KDnuggets.
Related:
- The Hard Problems AI Can’t (Yet) Touch
- Does Deep Learning Come from the Devil?
- MetaMind Competes with IBM Watson Analytics and Microsoft Azure Machine Learning
- Deep Learning and the Triumph of Empiricism
- The Myth of Model Interpretability
- (Deep Learning’s Deep Flaws)’s Deep Flaws
- Data Science’s Most Used, Confused, and Abused Jargon
Do you need a quick long or short term Loan with a relatively low interest rate as low as 3%? We offer business Loan, personal Loan, home Loan, auto Loan,student Loan, debt consolidation Loan e.t.c. no matter your credit score.
SvarSlettPersonal Loans (Secure and Unsecured)
Business Loans (Secure and Unsecured)
Consolidation Loan and many more.
Contact US for more information about Loan offer and we will solve your financial problem. contact
Asia Loan Company Ltd
asialoancompanyltd@gmail.com
Call/Whats-App +919319926618
Dr. Sipos Csaba